Logs Aggregation
Since WaveMaker is built on Java, we use Slf4j and logback Java libraries to generate the required logs at the platform level.
All the logs generated by the microservices are aggregated by integrating the Elasticsearch Fluentd, and Kibana (EFK) Stack.
EFK Stack
One of the most popular centralized logging solutions is the Elasticsearch, Fluentd, and Kibana (EFK) stack.
- Elasticsearch: This is is very efficient when it comes to dealing with huge volumes of data. We can easily filter the required Logs.
- Fluentd: Collects the application logs, transforms them into the required format, and pushes the transformed data to Elasticsearch.
- Kibana: Since data can't be directly accessed from Elasticsearch, Kibana provides a powerful UI that helps in accessing or visualizing the logs.
We will be focusing more on Kibana as Elasticsearch and Fluentd are only used as a part of the integration.
Architecture
The below image shows the architecture of the EFK stack
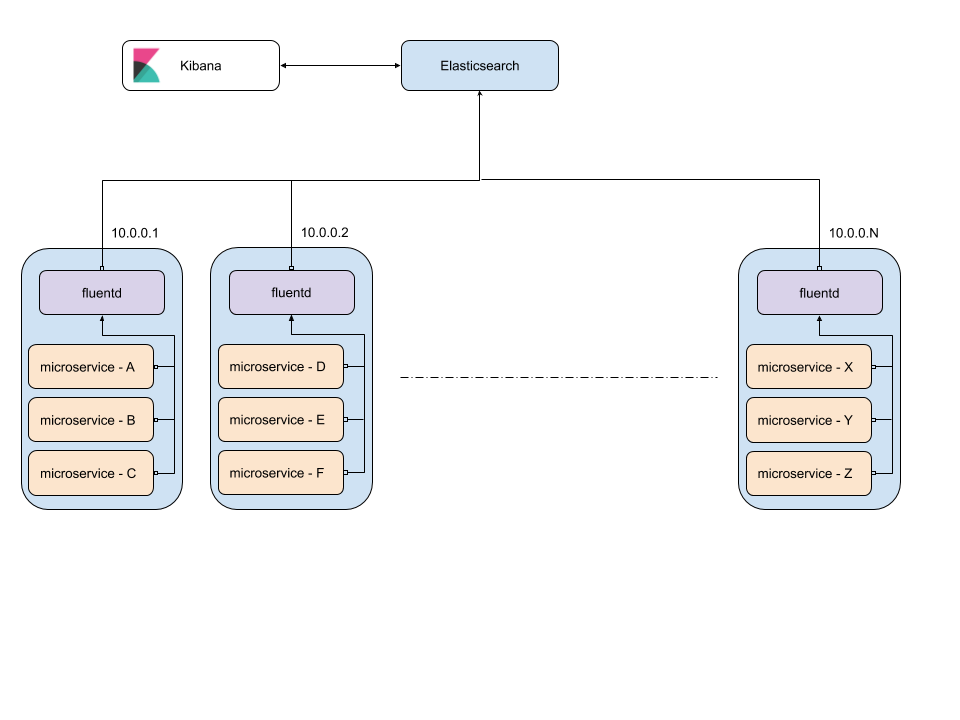
Here, The microservice containers labeled A-Z are spread across instances 10.0.0.1 - 10.0.0.N
Every instance contains a "fluentd" container that collects logs from the microservices present in the same instance.
Then, fluentd transforms and pushes this data to the Elasticsearch
Finally, Kibana can directly access the logs as it is connected to Elasticsearch